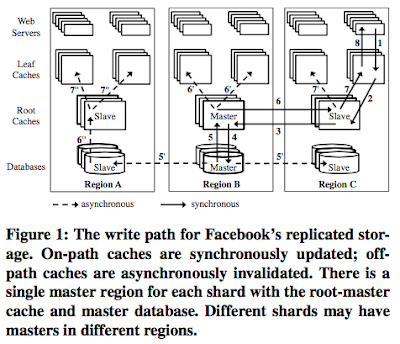
Paper review: Building Consistent Transactions with Inconsistent Replication (SOSP'15)

This paper investigates an interesting and promising research problem: how can we implement distributed transactions more efficiently by performing a cross-layer design of the transaction protocal/layer with the underlying distributed storage protocol/layer? This idea is motivated by the observation that there is wasted/duplicated work done both at the transaction layer and at the storage layer. The transaction layer already provides ordering (i.e., linearizability), and, if you look at the distributed storage layer, it also provides strongly consistent replication which orders/linearizes updates often with Paxos. The paper argues that this is overlapping functionality, and leads to higher latency and lower throughput. Ok, at this point, we have to take a step back and realize that we cannot avoid all coordination between the two layers. The distributed storage layer needs to be consistent with the order of updates at the transaction layer, because it serves reads and you like it to